How to Fine-Tune Open Source LLMs for My Specific Purpose

Anson Park
10 min read
∙
Dec 20, 2023
The latest LLaMA models, known as Llama2, come with a commercial license, increasing their accessibility to a broader range of organizations. Moreover, new methods enable fine-tuning on consumer GPUs with restricted memory capacity.
This democratization of AI technology is essential for its widespread adoption. By removing entry barriers, it allows even small businesses to develop tailored models that align with their specific requirements and financial constraints.

Fine-tuning an open-source Large Language Model (LLM) like Llama2 typically involves the following steps:
Understanding Llama2: This model is a collection of second-generation open-source LLMs from Meta, designed for a wide range of natural language processing tasks.
Setting Up: Install necessary libraries such as
accelerate,peft,bitsandbytes,transformers, andtrl.Model Configuration: Choose a base model from Hugging Face, such as NousResearch’s LLaMA-2-7b-chat-hf, and select a suitable dataset for fine-tuning.
Loading Dataset and Model: Load the chosen dataset and the Llama2 model using 4-bit precision for efficient training.
Quantization Configuration: Apply 4-bit quantization via QLoRA, which involves adding trainable Low-Rank Adapter layers to the model.
Training Parameters: Configure various hyperparameters like batch size, learning rate, and training epochs using
TrainingArguments.Model Fine-Tuning: Use the SFT Trainer from the TRL library for Supervised Fine-Tuning (SFT), providing the model, dataset, PEFT configuration, and tokenizer.
Saving and Evaluation: After training, save the model and tokenizer, and evaluate the model's performance.
This process requires a balance of technical knowledge in machine learning, programming skills, and understanding of the specific requirements of the task at hand.
Let's take a closer look. The fine-tuning example below comes from a tutorial on brev.dev. Greate work 👍🏻👍🏻
Data Preparation
Data is incredibly crucial! For your custom LLM to align with its intended use, you need to carefully prepare training data for fine-tuning that's tailored to the characteristics of your business, product, or service. This process is vital yet challenging. You can view fine-tuning data as being composed of pairs of inputs and outputs.
Install the necessary packages
Install the necessary packages as follows. The open-source ecosystem for LLM utilization is evolving rapidly.
Hugging Face Accelerate
Hugging Face's Accelerate library is a tool designed to simplify and optimize the training and usage of PyTorch models across various hardware configurations, including multi-GPU, TPU, and mixed-precision setups.
Weights & Biases for tracking metrics
Weights & Biases (W&B) is an AI developer platform designed to enhance the efficiency and effectiveness of building machine learning models.
Load the prepared dataset
Load the prepared fine-tuning data.
Load Base Model
Load the base model of your choice. I have selected mistralai/Mixtral-8x7B-v0.1.
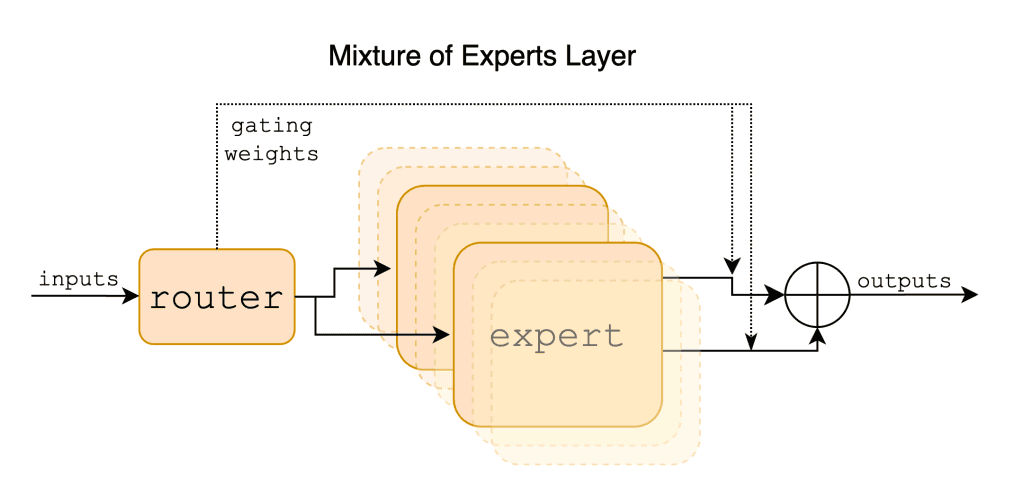
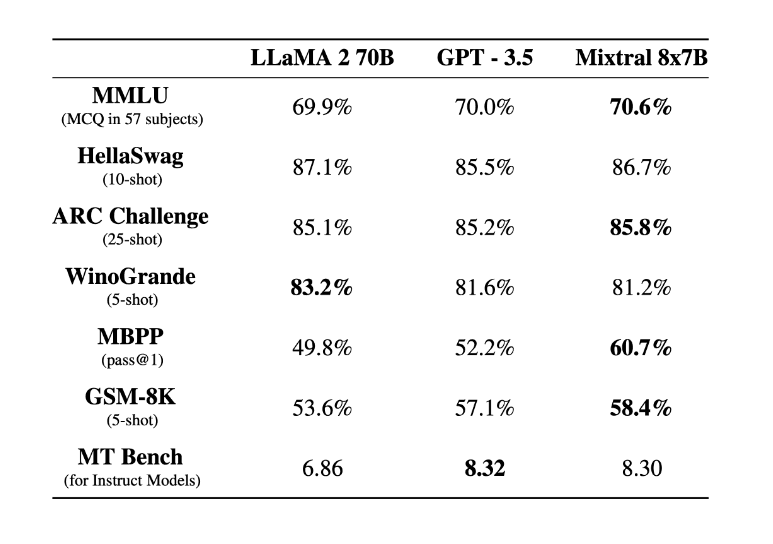
The Mixtral-8x7B LLM, a part of the Mistral AI series, is a significant advancement in generative language models. Here are some key details about the model:
Architecture and Performance: Mixtral-8x7B is a pretrained generative model, specifically a Sparse Mixture of Experts. It has been tested and shown to outperform the Llama2 70B model on most benchmarks.
Compatibility and Usage: The repository contains weights compatible with the vLLM serving of the model and the Hugging Face Transformers library.
Optimizations and Precision: By default, the Transformers library loads the model in full precision. However, optimizations available in the Hugging Face ecosystem can further reduce memory requirements for running the model.
Model Specifications: The Mixtral-8x7B model is a pretrained base model without any moderation mechanisms and features a substantial size of 46.7 billion parameters
Prompt Template & Tokenization
Prepare the tokenizer. After reviewing the length distribution of samples in your dataset, it's essential to establish a suitable value based on this analysis. The prompt's format can be tailored to align with the specific objectives of using the LLM.
Set Up LoRA
In language model development, fine-tuning an existing model for a specific task using specific data is standard. This might entail adding a task-specific head and updating neural network weights through backpropagation, different from training a model from scratch where weights start randomly initialized. Full fine-tuning, updating all layers, yields the best results but is resource-heavy.
Parameter-efficient methods like Low Rank Adaptation (LoRA) offer a compelling alternative, sometimes outperforming full fine-tuning by avoiding catastrophic forgetting. LoRA fine-tunes two smaller matrices approximating the pre-trained model’s larger weight matrix.
QLoRA, a more memory-efficient variant, uses quantized 4-bit weights for the pretrained model.
Both LoRA and QLoRA are part the Hugging Face PEFT library, and their combination with the TRL library streamlines the process of supervised fine-tuning.
Low-Rank Adaptation (LoRA) is an efficient technique used for fine-tuning Large Language Models (LLMs). Here's a detailed look at LoRA:
Concept and Application: LoRA is a method for fine-tuning LLMs in a more efficient manner compared to traditional fine-tuning methods. It addresses the challenge of adjusting millions or billions of parameters in LLMs, which is computationally intensive. LoRA proposes adding and adjusting a small set of new parameters, instead of altering all the parameters of the model.
Mechanism: Practically, LoRA involves introducing two smaller matrices
AandBin place of adjusting the entire weight matrixWof an LLM layer. For example, for a layer with a40,000 x 10,000weight matrix, LoRA would useA: 40,000 x 2andB: 2 x 10,000, resulting in a significant reduction in the number of parameters to tune. This approach simplifies the fine-tuning process by focusing only onAandB. The updated weight matrix is represented asW' = W + A * B, introducing a low-rank structure that captures the necessary changes for the new task and reduces the training parameters.Advantages: LoRA's efficiency stems from training only a small number of parameters, making it faster and less memory-intensive than conventional fine-tuning. Its flexibility allows for selective adaptation of different model parts, such as specific layers or components, offering a modular approach to model customization.
LoRA stands out as a 'smart hack' in machine learning for updating large models efficiently by focusing on a manageable set of changes, streamlining the process through linear algebra and matrix operations.
Start Training!
Let's start the training now!
—
In this post, we've explored the overall process and concepts of how to fine-tune open-source LLMs.
In practice, fine-tuning doesn't end with just one attempt. It involves preparing various types of datasets, setting different combinations of hyperparameters, fine-tuning numerous model versions, and comparing their performances. Ultimately, this process helps in selecting the most suitable model for production deployment. It's indeed a long and challenging journey.
At DeepNatural, we plan to offer a tool through LangNode that enables even those without programming skills to fine-tune open-source LLMs. Stay tuned for more updates!
References:
Written by Anson Park
CEO of DeepNatural. MSc in Computer Science from KAIST & TU Berlin. Specialized in Machine Learning and Natural Language Processing.
More from Anson Park

What is LLMOps?
LLMOps, or Large Language Model Operations, is a specialized field emerging at the intersection of AI and operational management. It primarily focuses on the lifecycle management of large language ...
Anson Park
∙
5 min read
∙
Dec 8, 2023

Trending Open Source LLMs in 2024
Open-source AI, including LLMs, has played a crucial role in the advancement of AI technologies. Most of the popular LLMs are built on open-source architectures like Transformers, which have been foun ...
Anson Park
∙
5 min read
∙
Dec 19, 2023

Which LLM is Better - Open LLM Leaderboard
The Open LLM Leaderboard is a significant initiative on Hugging Face, aimed at tracking, ranking, and evaluating open Large Language Models (LLMs) and chatbots. This leaderboard is an essential resour ...
Anson Park
∙
8 min read
∙
Jan 7, 2023

Which LLM is better - Chabot Arena
Chatbot Arena is a benchmarking platform for Large Language Models (LLMs), utilizing a unique approach to assess their capabilities in real-world scenarios. Here are some key aspects of Chatbot Arena ...
Anson Park
∙
7 min read
∙
Jan 9, 2023