내 사용 목적에 맞게 오픈 소스 LLM을 파인튜닝하는 방법

Anson Park
10분
∙
2023. 12. 20.
Llama2 모델은 상업적 사용을 위한 라이선스로 공개되어 더 많은 기업들이 LLM을 활용할 수 있게 되었습니다. 추가적으로, 이 모델은 메모리 용량이 비교적 작은 GPU에서도 효율적으로 파인튜닝할 수 있는 새로운 방법을 지원합니다.
AI 기술의 민주화는 더 넓은 범위에서 AI가 활용되는데 필수적인 요소입니다. 진입 장벽이 낮아지게 되면 기업들은 자신들의 특정 비즈니스 요구와 재정적 한계를 고려하여 맞춤형 모델을 개발할 수 있습니다.

아래 순서는 이번 글에서 다루고 있는, Llama2와 같은 오픈 소스 LLM을 파인튜닝하기 위한 일반적인 단계 입니다:
Llama2 확인: 이 모델은 광범위한 자연어 처리 작업을 위해 설계된 Meta의 2세대 오픈 소스 LLM 모음입니다.
환경 설정하기:
accelerate,peft,bitsandbytes,transformers,trl등 필요한 라이브러리를 설치합니다.모델 구성: 허깅 페이스에서 NousResearch의 LLaMA-2-7b-chat-hf와 같은 베이스 모델을 선택하고 파인튜닝을 위해 적합한 데이터셋을 준비합니다.
데이터셋 및 모델 로드하기: 효율적인 학습을 위해 4비트 정밀도를 사용하여 선택한 데이터 세트와 Llama2 모델을 로드합니다.
양자화 구성: 모델에 훈련 가능한 Low-Rank Adapter 레이어를 추가하는 QLoRA를 통해 4비트 양자화를 적용합니다.
훈련 파라미터:
TrainingArguments를 사용하여batch size,learning rate,training epoch과 같은 다양한 하이퍼파라미터를 설정합니다.모델 미세 조정: 모델, 데이터 세트, PEFT 설정 및 토크나이저 제공하는 TRL 라이브러리의 SFT Trainer를 사용하여 Supervised Fine-Tuning(SFT)을 수행합니다.
저장 및 평가: 학습이 끝나면 모델과 Tokenizer를 저장하고 모델의 성능을 평가합니다.
이 과정에는 머신 러닝에 대한 기술 지식, 프로그래밍 기술, 그리고 당면한 작업의 특정 요구 사항에 대한 이해가 균형을 이루어야 합니다.
자세히 살펴보겠습니다. 아래의 파인튜닝 예제는 brev.dev의 튜토리얼에서 가져온 것입니다. Great work! 👍🏻👍🏻
데이터 준비
데이터는 매우 중요합니다! 내가 목표하는 비즈니스, 제품, 서비스에 적합하도록 LLM을 파인튜닝하기 위해서는 학습 데이터를 신중하게 준비해야 합니다. 이 과정은 매우 중요하지만 까다롭습니다. 기본적인 파인튜닝 데이터셋은 한 쌍의 입력과 출력 텍스트로 구성되어 있습니다.
필요한 패키지 설치하기
LLM 활용을 위한 오픈소스 생태계는 빠르게 진화하고 있죠! 다음과 같이 필요한 패키지를 설치합니다.
허깅 페이스 Accelerate
허깅 페이스의 Accelerate 라이브러리는 멀티 GPU, TPU, 혼합 정밀도(Mixed Precision) 설정 등 다양한 하드웨어 구성에서 PyTorch 모델을 학습시키고 간소화 및 최적화하도록 설계된 도구입니다.
Weights & Biases를 이용한 메트릭 추적
Weights & Biases (W&B)은 머신러닝 모델 구축의 효율성과 효과를 높이기 위해 설계된 AI 개발자 플랫폼입니다.
데이터셋 로드
준비된 파인튜닝 데이터셋을 로드합니다.
베이스 모델 로드하기
선택한 베이스 모델을 로드합니다. mistralai/Mixtral-8x7B-v0.1을 선택했습니다.
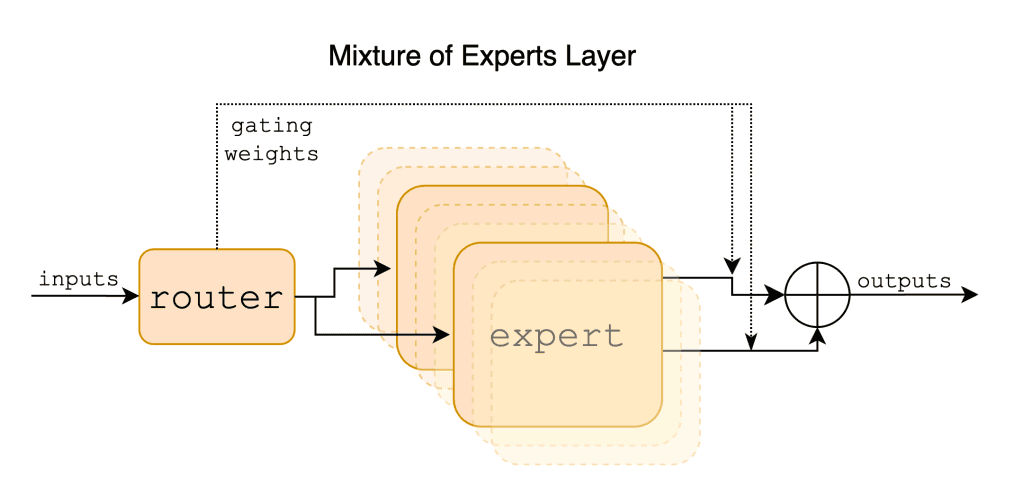
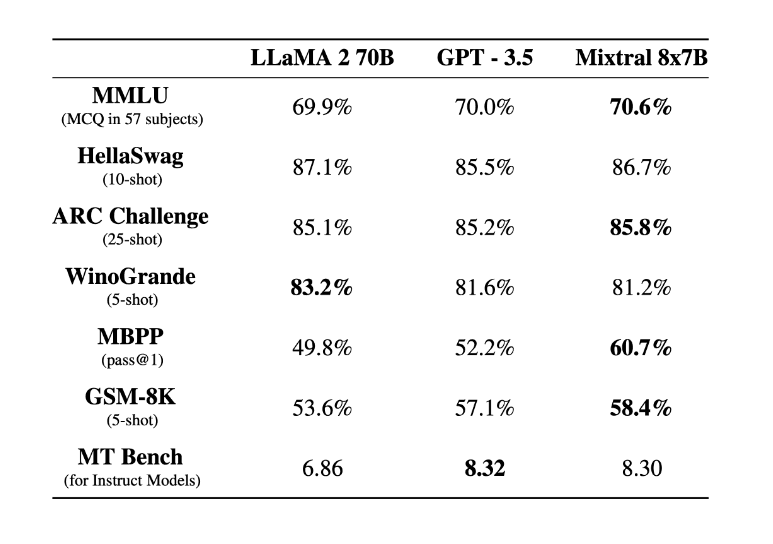
Mistral AI 시리즈의 일부인 Mixtral-8x7B LLM은 최근 벤치마크에서 높은 성능을 기록하고 있는 모델입니다. 다음은 믹스트랄 모델에 대한 몇 가지 주요 특징입니다:
아키텍처 및 성능: Mixtral-8x7B는 사전 학습된 생성 모델로 Sparse Mixture of Experts(SMoE) 아키텍처를 제안합니다. 테스트 결과 대부분의 벤치마크에서 라마2 70B 모델보다 성능이 뛰어난 것으로 나타났습니다.
호환성 및 사용법: 저장소에는 해당 모델의 vLLM 서비스 및 Hugging Face Transformers 라이브러리와 호환되는 가중치(Weights)가 포함되어 있습니다.
최적화 및 정밀도: 기본적으로 Transformers 라이브러리는 모델을 전체 정밀도로 로드합니다. 하지만 허깅 페이스 에코시스템에서 제공되는 최적화를 통해 모델 실행에 필요한 메모리 요구 사항을 더욱 줄일 수 있습니다.
모델 사양: Mixtral-8x7B 모델은 모더레이션 메커니즘이 없는 사전 학습된 기본 모델이며 467억 개의 파라미터로 구성된 상당한 크기의 모델입니다.
프롬프트 템플릿 & 토크나이저
Tokenizer를 준비합니다. 데이터 세트에서 샘플의 길이 분포를 검토한 후에는 이 분석을 바탕으로 적절한 max_length 값을 설정하는 것이 필요합니다. 프롬프트의 형식은 LLM을 사용하는 특정 목적에 맞게 조정할 수 있습니다.
LoRA 설정
언어 모델 개발에서는 특정 데이터를 사용하여 특정 작업에 맞게 기존 모델을 파인튜닝하는 것이 일반적입니다. 여기에는 태스크에 적합한 헤드(Head)를 추가하고 역전파(Backpropagation)를 통해 신경망 가중치(Weights)를 업데이트하는 작업이 포함되는데, 이는 가중치가 무작위로 초기화되는 처음부터 모델을 훈련하는 것과는 다릅니다. 모든 레이어를 업데이트하는 전체 파인튜닝은 최상의 결과를 얻을 수 있지만 리소스를 많이 사용합니다.
Low Rank Adaptation (LoRA)과 같은 매개변수 효율적 방법은 치명적인 망각(Catastrophic Forgetting)을 방지하여 때때로 전체 파인튜닝 보다 더 나은 성능을 제공하는 강력한 대안입니다. LoRA는 사전 학습된 모델의 큰 가중치 행렬에 근사한 두 개의 작은 행렬을 파인튜닝 합니다.
메모리 효율성이 더 높은 변형인 QLoRA는 사전 학습된 모델에 양자화된 4비트 가중치를 사용합니다.
LoRA와 QLoRA는 모두 Hugging Face PEFT 라이브러리에서 지원하며, TRL 라이브러리와 함께 사용하면 Supervised Fine-Tuning을 용이하게 합니다.
컨셉: LoRA는 기존의 방법에 비해 더 효율적인 방식으로 LLM을 파인튜닝하는 방법입니다. 이 방법은 LLM이 가지고 있는 수백만 또는 수십억 개의 방대한 파라미터를 튜닝해야하는 문제를 해결합니다. LoRA는 모델의 모든 파라미터를 변경하는 대신 소수의 새로운 파라미터 세트를 추가하고 튜닝하는 것을 제안합니다.
메커니즘: 실제로 LoRA는 LLM 레이어의 전체 Weight Matrix
W를 업데이트하는 대신 두 개의 작은 행렬A와B를 도입하는 방식을 사용합니다. 업데이트된 가중치 행렬은W' = W + A x B로 표시되며, 새로운 작업에 필요한 변경 사항을 포착하고 학습 파라미터를 줄이는 low-rank structure를 도입합니다. 예를 들어, Weight Matrix가40,000 x 10,000인 레이어의 경우 4백만개의 전체 파라미터를 업데이트하는 대신, LoRA는 k=2를 가정했을 때A: 40,000 x 2와B: 2 x 10,000을 사용하므로 튜닝할 매개변수의 수가 10만으로 크게 줄어듭니다. 이 접근 방식은A와B에만 집중하여 파인튜닝 프로세스를 간소화합니다.장점: LoRA는 적은 수의 파라미터를 학습함으로써 전통적인 파인튜닝보다 더 빠르고 메모리 사용도 줄일 수 있습니다. 이는 특정 레이어나 구성 요소를 선택적으로 적용할 수 있는 유연성을 갖추고 있어, 모델을 커스터마이징하는 데 있어 모듈을 조합하는 방식을 가능하게 합니다.
LoRA는 소수의 변경 사항에 주목하고, 선형 대수 및 행렬 연산을 활용해 프로세스를 간결하게 함으로써 대규모 모델을 효과적으로 업데이트하는 머신러닝의 "Smart Hack"으로 인식되고 있습니다.
파인튜닝 시작!
이제 학습을 시작합니다!
—
이 글에서는 오픈 소스 LLM을 파인튜닝하는 방법에 대한 전반적인 프로세스와 개념을 살펴봤습니다.
실제로 파인튜닝은 한 번의 시도로 끝나지 않습니다. 목적에 부합하는 데이터 세트를 기획 ∙ 구축하여, 다양한 하이퍼파라미터 조합 및 프롬프트 템플릿으로, 여러 베이스 모델 버전을 파인튜닝해보면서, 성능을 비교 평가하는 과정이 필요합니다. 상당히 길고 어려운 과정이죠. 궁극적으로 이 프로세스를 통해 가장 적절하게 파인튜닝된 모델을 프로덕션 환경에 배포할 수 있게 됩니다.
References:
Written by Anson Park
CEO of DeepNatural. MSc in Computer Science from KAIST & TU Berlin. Specialized in Machine Learning and Natural Language Processing.
Anson Park 님의 글 더보기

LLMOps란 무엇인가요?
LLMOps는 Large Language Model Operations의 줄임말 입니다. AI와 운영 관리가 만나는 지점에서 생겨난 특화된 분야입니다. 이는 개발 및 운영 환경에서 대규모 언어 모델의 라이프 사이클을 관리하는 데 주력하고 있습니다. OpenAI의 GPT-4, Meta의 Llama2, Google의 Gemini와 같은 LLM이 자연어처리 ...
Anson Park
∙
5분
∙
2023. 12. 8.

2024년 주목할 오픈 소스 LLM
특정 관점에서 LLM은 크게 2가지로 분류할 수 있습니다. 독점(Proprietary) 모델과 오픈소스(Open Source) 모델. 독점(Proprietary) LLM: 예를 들어 OpenAI의 GPT 모델, Google의 Gemini, Anthropic의 Claude와 같은 독점 LLM은 특정 회사에서 개발 및 유지 관리됩니다. 이들은 제어된 개발 ...
Anson Park
∙
5분
∙
2023. 12. 19.

어떤 LLM의 성능이 더 좋은가요 - 오픈 LLM 리더보드
오픈 LLM 리더보드는 허깅페이스가 주도하는 중요한 프로젝트입니다. 대규모 언어 모델의 순위를 매기며 평가하는 것을 목표로 합니다. 이 리더보드는 다양한 오픈 소스 LLM에 대한 포괄적이며 최신 비교 정보를 제공하면서 AI 커뮤니티에 꼭 필요한 자원이 되고 있습니다. 이 플랫폼을 활용하면, 사용자들은 자신의 모델을 GPU 클러스터를 통해 자동으로 평가받을 ...
Anson Park
∙
8분
∙
2023. 1. 7.

어떤 LLM의 성능이 더 좋은가요 - 챗봇 아레나
Chatbot Arena는 대규모 언어 모델(LLM)을 위한 벤치마킹 플랫폼으로, 실제 시나리오에서 그 기능을 평가하기 위한 고유한 접근 방식을 활용합니다. 다음은 챗봇 아레나의 몇 가지 주요 측면입니다. Chatbot Arena는 보다 실용적이고 사용자 중심적인 방식으로 오픈 소스 LLM을 평가하도록 설계되었습니다. 이는 문제의 개방형 특성과 자동 응답 ...
Anson Park
∙
7분
∙
2023. 1. 9.